И — 0418,
Visual2000 · Архив статей А.Колесова & О.Павловой
Андрей Колесов
© 1999, Андрей КолесовКак было сказано выше, при работе со символьными переменными в VB постоянно происходит преобразование данных из ANSI в Unicode и обратно. Рассмотрим такой пример:
strValue$ = "И" ' преобразование из ANSI в Unicode Print strValue$ ' преобразование из Unicode в ANSI
Проблема здесь заключается в неоднозначности вариантов такого
преобразования. Дело в том, что русскому символу
И соответствует в ASNI/ASCII
значение 200 (C8 в шестнадцатиричной системе). Однако этому же коду соответствуют
символы
![]() (для западноевропейских языков, кодовая таблица 1252) и
(для западноевропейских языков, кодовая таблица 1252) и
![]() (для
восточноевропейских языков, кодовая таблица 1250). В тоже время все эти три
символа имеют разный Unicode (шестнадцатиричное представление):
(для
восточноевропейских языков, кодовая таблица 1250). В тоже время все эти три
символа имеют разный Unicode (шестнадцатиричное представление):
И — 0418,
![]() — 00C8,
— 00C8,
![]() — 0107.
— 0107.
В приложениях, использующих ANSI-коды (например, Word 6.0, среда VB или Notepad), изменение изображения этого символа достигается простой заменой шрифта самим пользователем. В приложениях, использующих Unicode (Word 97), выбор изображения символа (выбор шрифта) выполняется автоматически самой программой в соответствии с кодом символа.
Итак, вопрос формулируется следующим образом: по каким правилам происходит преобразование кодов? Ответ на него может быть интересен тем, кто создает приложения для интернациональных приложений (которые могут работать не только внутри России) и тем, кто пишет макросы для многоязычных документов в Word 97.
В VB/VBA преобразование символьных кодов в явном виде выполняется двумя способами:
1. Функциями Chr/Asc, которые преобразуют числовой ASCII-код в строковую переменную (два двоичных байта, один символ) и наоборот.
a$ = Chr(200) ' один Unicode-символ, два байта AsCode% = Asc(a$) ' число 200
2. Функцией StrConv, которая делает такие же преобразования в зависимости от ее второго параметра, но такая операция выполняется над всеми байтами строки:
a$ = "Петя" ' строка Unicode-кодов b$ = StrConv(a$, vbFromUnicode) ' строка ANSI-кодов c$ = StrConv(b$, vbUnicode) ' строка Unicode-кодов Print LenB(a$); LenB(b); LenB(c$) ' 8 4 8 — число байт Print (a$ = c$) ' True, переменные равны
Так вот, для VB 5.0 и VBA 5.0 (который входит в состав MS Office 97) в обоих случаях режимом преобразования управляет параметр "ANSI кодовая таблица" (ACP), который записан в системном реестре по адресу:
HKEY_LOCAL_MACHINE\System\CurrentControlSet\Contol\Nls\CodePage\
Для VB 6.0 (и, вероятно, для VBA в составе MS Office 2000) для функций Chr/Asc используется тот же параметр ACP, а для StrConv — параметр "региональные установки" (LocaleID), который хранится в системном реестре по адресу:
HKEY_LOCAL_MACHINE\System\CurrentControlSet\Contol\Nls\Locale\
Оба этих параметра определяются в Windows 9x при начальной установке системы, но при этом могут быть изменены (в международных версиях) прямой коррекцией реестра, а LocaleID — через окно Control Panel | Regional Setting.
Значения этих параметров в системе можно определить в программе с помощью API-функций:
Declare Function GetSystemDefaultLCID& Lib "kernel32" () Declare Function GetACP& Lib "kernel32" ()
Следует также отметить, что параметр ACP в VB 6.0 влияет на режим перекодировки при неявных операциях преобразования кодов типа:
strValue$ = "Петя": Print strValue$
А параметр LocaleID управляет режимом преобразования для операций UCase/LCase (и их аналога StrConv), а также при выполнении операций сравнения — InStr, StrComp — в режиме Text Compare.
В VB 6.0 реализован расширенный вариант функции StrConv — можно использовать LocaleID, установленный в системе, или задать его в явном виде:
b$ = StrConv(a$, vbFromUnicode) ' системный LocaleID с$ = StrConv(a$, vbFromUnicode, &H419) ' Russia
Из сказанного выше можно определиться параметры приложения или операционной системы, которые влияют представление (для Win16) или преобразование (Win32) национальных символов:
Группа языков |
Win16, ANSI | Win32, Unicode |
|
| Тип шрифта | Кодовая таблица | LocaleID (региональные установки) | |
| Central European | Courier CE | cp1250 | &h415 (Польша) |
| Cyrillic | Courier Cyr | cp1251 | &h419 (Россия) |
| Western | Courier | cp1252 | &h409 (США) |
При этом следует подчеркнуть следующие моменты:
Все обстоит достаточно просто при преобразовании из ANSI в Unicode. выполнение следующего кода приведет к формированию разных двоичных строк в зависимости от установленной кодовой таблицы:
strValue$ = "И" Print Hex$(AscW(strValue$))
Для cp1250 будет напечатано 10C, для cp1251 — 418, для cp1252 — C8. В то же время нужно иметь в виду специфику выполнения такого кода:
strValue1$ = Chr(200) strValue2$ = StrConv(ChrB(200), vbUnicode) Print (strValue1$ = strValue2$)
При работе в среде VB 5.0 переменные strValue1$ и strValue2$ будут всегда равны, в среде VB 6.0 — только в случае согласованных значений кодовой таблицы и региональных установок.
Гораздо более запутанно обстоит дело с преобразованием из Unicode в ANSI. Выполним такой программный код:
v1250$ = ChrW(&H010C) v1251$ = ChrW(&H0418) v1252$ = ChrW(&H00C8)
Здесь формироваются три переменную, состоящие из одного символа —
соответственно
![]() ,
И,
,
И,
![]() — каждой из которых соответствует один и тот же ANSI-
код — 200 (&h00C8). Однако, что же получится, если выполнить далее такую
операцию:
— каждой из которых соответствует один и тот же ANSI-
код — 200 (&h00C8). Однако, что же получится, если выполнить далее такую
операцию:
Print Asc(v1250$); Asc(v1251$); Asc(v1252$)
Казалось бы, должно получиться "200 200 200", но на самом деле это не так _ результат будет выглядеть следующим образом:
|
Переменная (Unicode, изображение) |
Результат выполнения функции Asc для различных кодовых таблиц, десятичное/шестнадцатиричное представление | ||
| cp1250 | cp1251 | cp1252 | |
| v1250$ (&h010C, |
200/C8 | 63/3F | 69/45 |
| v1251$ (&h0418, И) | 67/43 | 200/С8 | 69/45 |
| v1252$ (&h00C8, |
67/43 | 63/3F | 200/C8 |
Из этого можно сделать такой вывод: Правильное преобразование из Unicode в ANSI выполняется только в том случае, когда код таблицы Unicode (старший байт-код) соответствует кодовой таблице (или параметру региональных установок для функции StrConv в VB6). Возможно, Microsoft так и хотел сделать, но такая задумка выглядит весьма странно — вполне вероятно в данном случае допущена просто ошибка.
Может показаться, что вся приведенная здесь информация имеет скорее напоминает теоретические размышления, однако практическое применение всего этого проиллюстрировано во врезке "Как перекодировать символы в Word 97". Следует также упомянуть о том, что в составе Win API имеется целый набор фунций работы со строковыми переменными, но в целом он не очень значительно расширяет возможности встроенных VB-функций. Пользоваться последними гораздо проще.
Преобразование кодов в Windows выполняется довольно странно
Наверное, многие из читателей встречались с ситуацией, когда в результате копирования или перезаписи текстов неожиданно происходили такие странные преобразования текста:
из
Привет читателям!
в
![]()
а потом в
I?eaao ?eoaoaeyi!
а еще в какой-то момент в
????????????????!
Проиллюстрирую причины таких неожиданных преобразований на примере MS Office и VBA. Однако следует отметить, что обнаруженные здесь проблемы характерны не только для VB и их причина заключается в специфике работы системных функций Windows API.
Для выполнения данного примера вам понадобится Word 6.0 и Word 97. Загрузите обе программы. В документе Word 6.0 введите три одинаковые строки с подобным набором символов:
Вы видите нормальные русские символы, если у вас установлен какой-то шрифт кириллицы, например, Courier Cyr (Courier — чтобы были символы одной ширины). Теперь выделите вторую строку текста установите для нее шрифт Courier (западноевропейский набор или Western), а для третей строки — Courier CE (восточноевропейский, который по-английски называется "центральноевропейский"). Вы увидите такой текст:
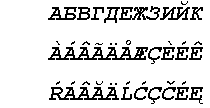
Сохраните документ как DocWord6.doc. Теперь сохраните этот же документ в формате "Просто текст" (DocWord6.txt) и закройте. А теперь заново прочитайте DocWord6.txt и вы увидите:
АБВГДЕЖЗИЙК
АБВГДЕЖЗИЙК
АБВГДЕЖЗИЙК
Ситуация понятна: в этом случае мы имеем дело с тремя строками, в которых каждый символ задан однобайтовыми ANSI-кодами со значениями 128-138. Двоичные коды байтов во всех строках одинаковы и их графическое изображение зависит от установки пользователем типа шрифта. В TXT-файле мы просто убрали форматирование — установили одинаковый шрифт для всех строк. Обратите внимание, что формирование содержимого TXT-файла никак не зависит от установленной кодовой таблицы или региональных установок. (TXT-файлы лучше посмотреть простым редактором типа Notepad).
Теперь скопируйте через буфер обмена содержимое DocWord6.doc в новый документ DocWord8.doc и далее проделайте описанные выше манипуляции по созданию и чтению TXT-файла. В DocWord8.doc вы увидите те же строки:
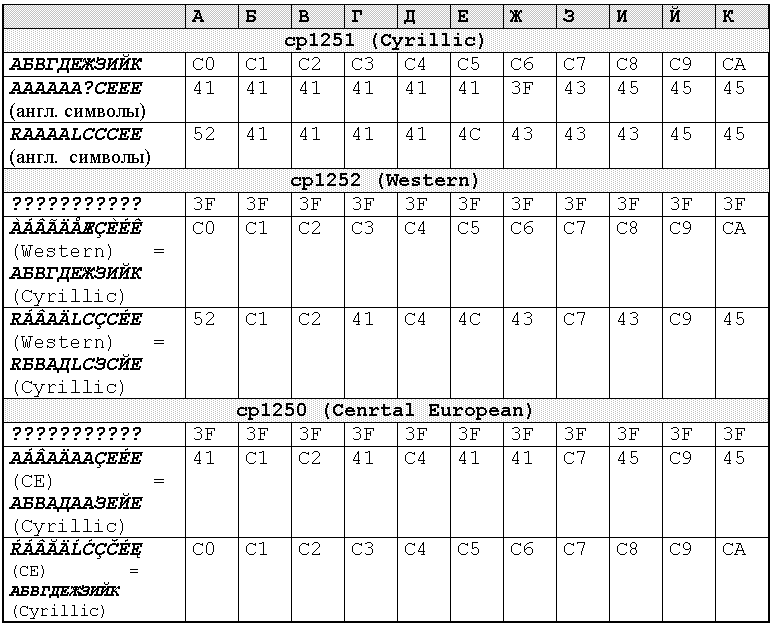
а вот в DocWord8.txt будет нечто новое:
АБВГДЕЖЗИЙК
AAAAAA?CEEE
RAAAALCCCEE
В данном случае мы имеем дело с такой ситуацией: в результате последовательности преобразования ANSI -> Unicode -> ANSI для двух последних строк мы получили, что результирующий вариант не соответствует исходному. Чего, в общем-то, не должно быть.
Такое преобразование данных объясняется следующим образом. При копировании строк из Word 6.0 в Word 97 символьные данные были преобразованы из ANSI в Unicode, при этом учитывался установленный тип шрифта — Script — для каждой строки (то есть соответствующая ему кодовая таблица — 1251, 1252 и 1250). Таким образом три одинаковые двоичные строки байтов ANSI-кодов были преобразованы в три РАЗНЫЕ строки Unicode-кодов, а те в свою очередь — в РАЗНЫЕ строки ANSI-кодов.
Обратное же преобразование из Unicode в ANSI (при сохранении в виде TXT- файла) было произведено по следующим правилам:
1. Для русского кода исходный ANSI-код был восстановлен правильно.
2. Для символов других языков коды верхней ASCII-таблицы (128-255) были преобразованы в 7-разрядное представление по правилу, когда расширенные варианты латинских символов, которые используются в европейских языках, заменяются на их основной вариант (например, разные варианты A — с крышкой, точкой, апострофом и пр. — заменяются на английскую A).
Правильное преобразование для русского кода объясняется тем, что в данном случае у нас в Windows 98 была установлена кодовая таблица кириллицы, cp1251. В случае cp1252 мы получили DocWord8.txt (Script=Cyrillic):
???????????
АБВГДЕЖЗИЙК
RБВAДLCЗCЙE
а для cp1250 (Script=Cyrillic):
???????????
AБВAДAAЗEЙE
АБВГДЕЖЗИЙК
Результаты проведенных преобразований приведены в таблице 3. Обратите внимание, что при чтении TXT-файла в Word 97 происходит обратная перекодировка из ANSI в Unicode в соответствии с текущей системной кодовой таблицы, то есть автоматически выбирается нужный тип шрифта Script. Поэтому для сравнения получаемых результатов в TXT-файле лучше пользовать редактором NotePad и устанавливать одинаковый тип шрифта.
Здесь мы видим, что символы, у которых нет "базового" аналога из таблицы
кодов 32-127, производится их замена на "?" (&h3F). Причем это касается не только
символов кодовой таблицы кириллицы, но и европейского символа
![]() (Unicode —
&h00C6).
(Unicode —
&h00C6).
Конечно, ситуация, когда правильное преобразование из Unicode в ANSI выполняется только для кодов, которые соответствуют кодовой таблице, установленной в Windows, представляется если не ошибочной, то, по крайней мере очень странной. Ведь в этом случае происходит потеря информации (разные исходные ANSI-коды заменяются одинаковыми): обратное восстановление исходного кода невозможно.
ВНИМАНИЕ! В ходе подготовки этой статьи была обнаружена ошибочная ситуация в работе Word 97. Когда я прочитал в Word 97 созданный ранее файл DocWord6.doc, то увидел такое его содержимое:
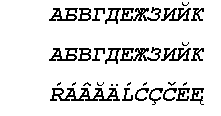
То есть вторая строка из западноевропеской записи превратилась в русскую. Это к вопросу о том, что от простого чтения в разных версиях Word содержимое документов может меняться...

Преобразование из Word 97 в TXT для разных кодовых таблиц (однойбайтовая ANSI-кодировка символов):
К сожалению, случай, когда довольно неожиданно происходит преобразование типа:
![]()
встречается довольно часто. В Word 6.0 восстановление исходного текста производится очень просто — установкой нужного шрифта. Но в Word 97 такой возможности нет: выбор шрифта (Cyrillic или Western) делается автоматически в зависимости от Unicode-кода. Как быть?
Для этого можно воспользоваться VBA и написать соответствующую макрокоманду, но на самом деле встроенных средств VBA недостаточно для полного решения такой задачи. Проблема заключается в том, что он может правильно преобразовывать из Unicode в ANSI только символы установленной в системе в данный момент кодовой таблицы, то есть по тем же правилам, что описаны выше.
Решение задачи на VB 6.0 (и Office 2000) выглядело бы следующим образом:
a$ = Selection.Text
RegionTo% = &H419 ' в какой код преобразовывать
For i% = 1 To Len(a$)
k1% = AscW(Mid(a$, i, 1)) ' Unicode
k2% = k1%\&h100 'старший байт кода
Select Case k2% ' в зависимости от типа кодовой таблицы
Case 4 ' Cyrillic
RegionFrom% = &H419 'Россия
Case 1 'Central European
RegionFrom% = &H415 'Польша
Case 0 ' Western
RegionFrom% = &H409 'США
Case Esle ' Все остальные
Stop ' неизвестный код
End Select
a1$ = StrConv(ChrW(k1%), vbFromUnicode, RegionFrom%)
Mid$(a$, i, 1) = StrConv(a1$, vbUnicode, RegionTo%)
Next i
Selection.Text = a$
Но для Word 97 оно не годится — в VBA 5.0 нет расширенного варианта функции StrConv. Хотя, возможно, в Office 2000 эта функция уже реализована. Тем не менее вариант преобразования из Western в Cyrillic (наиболее распространенный вариант искажения текстов) решается и в Word 97 достаточно просто:
a$ = Selection.Text
For i% = 1 To Len(a$)
k1% = AscW(Mid$(a$, i, 1))
If k1% > 255 Then ' код Cyrillic
a1$ = ChrW$(k1%)
Else ' код Western (ANSI=Unicode)
a1$ = Chr$(k1%)
End If
Mid$(a$, i, 1) = a1$
Next i
Selection.Text = a$
Тут я воспользовался тем, что для символов Western коды Unicode и ANSI равны. Впрочем, и для всех других случаев проблема перекодировки является вполне разрешимой — нужно просто самим составить таблицу Unicode-кодов для разных кодовых таблиц и написать достаточно простую программу их преобразования.